Overview
We have been tasked with proposing how we would re-engineer an aging SGI High Performance Computing platform. The platform is a 35 Node cluster running Red Hat 6.7 on each node with a Lustre file system mount and a /home file system presented via NFS from a Hierarchical Storage Node (over an FDR Infiniband network).
In addition to the existing cluster of Compute Nodes there is an SGI UV2000 4TB Memory Node with 256 CPU’s for processing large data sets.
The nodes are connected using a mix of 10G Fibre, 40/56G FDR Infiniband and 1G/10G Ethernet as shown in the following photos:

4 racks of CPU Nodes 

10G Fibre TOR, 56G Inifiband and 1G Ethernet 
10G Fibre Everywhere! 
Storage 700+ Disks
Current Config
The Compute Nodes are currently AMD 6278 16 core, 2.4GHz CPU’s with 256GB of RAM. There are four sockets and 64GB per CPU. These are very old and several generations behind so while they work, we propose to keep them as a “legacy” job queue and phase them out as they die. As this occurs new high performance Compute Nodes will be phased in to replace them.
Scheduling Software
The cluster runs PBS Pro 13 which is an old version. The current version available is v19. So there is an upgrade path and we will look at the costs of that in due course. But as scheduling software goes, there are plenty of others available in use in University, Research Institutes and Engineering Labs. One of the more popular Job Scheduling packages is Slurm. We will factor implementing the SLURM scheduler into our proposal due to its popularity and functionality.
Lustre File System
The cluster runs an old implementation of the Lustre FS to provide a high speed file system shared with all nodes in the cluster. This will need to be rebuilt on new hardware at some stage and with newer storage. So some research into the performance of current Storage technology will be required. The older units have 3TB drives and only the Metadata Servers access SSD’s in a Raid 1 mirror.
Current Issues
The aging cluster is not being fully utilized and this is partly due to:
- Poor performance of the CPU’s and their Floating Point capability
- The OS version running on them is RedHat 6.7 that means more recent software can’t be built on them until they at a Redhat 7 or 8 level.
Since the data sets are getting larger, the time to process is taking longer than the allowed time limit for the researches to process and analyse the data, a fast system will enable faster turn around of Job Results.
The client has commissioned an upgrade process to upgrade the cluster, so our changes will kick in after that.
Proposed Roadmap
After some research we came up with a viable road map to bring the HPC up to a modern fast platform for Life Sciences use and to validate this we have built an entire HPC as virtual machines using VMWare and documented the build process.
The proof of concept has allowed us to build and deploy a SLURM based HPC with a working Lustre filesystem in under a week (including HA support).
Workloads and MPI
An analysis of the Life-Science workloads shows there is very little MPI based software in use at present. This is changing over time but an EDR Infiniband network would not be fully utilized and the costs at this point in time do not justify it. However, the software is rapidly changing, heading into the Application Containerization space and in some cases with rapid/mass deployment capability. So we needed to factor that into the design for re-engineering in 24months time.
To help phase out much of the older equipment, our road map has addressed the following:
- Build and commission a new Lustre File server.
- Install a new smaller RDMA over Converged Ethernet (RoCE) Network for newer nodes and
- Backport FDR Infiniband for the Legacy Nodes.
- Install the new scheduler, login and build Nodes.
- Implement some high end GPU Compute Nodes
- Implement some large memory Compute Nodes.
- Roll out some basic Fast compute Nodes.
Lustre File server upgrade
For the MDS nodes, we have specified two new Intel servers with 256G RAM and a Direct Attach Storage flash storage array featuring 24 NVMe drives. The config will be a RAID-10, comprising an 11 drive stripe and then a mirror of that with some hot spares. Both servers will see the new storage as three LUN’s one for /lustre, /sw and /home filesystems will be provisioned. Some Hot Spare disks will cover disk failures when the hardware is out of maintenance.
To enable both new and old nodes to connect, Dual port ConnectX5 cards from Mellanox will enable 100G Ethernet on one port and FDR Infiniband on the other allowing all hardware to see the Lustre FS. When FDR is phased out the cards can be reconfigured for EDR IB if needed.
There will be four Object Storage Servers (OSS), they will connect to another Direct Attached storage array with about 750TB of disks. The Array will present to all four servers.
All the servers (MDS and OSS servers) will be configured with Corosync and Pacemaker for HA services. The MDS will comprise two servers in a HA config, while the OSS’s will be in two separate HA pairs.
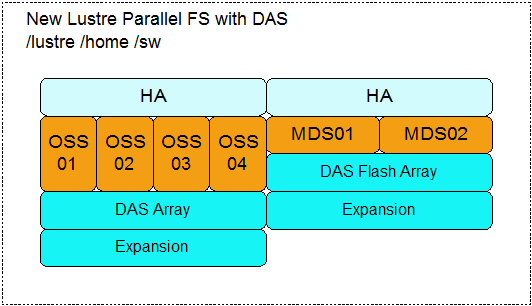
We are also going to create the home directory and software shares on Lustre as most jobs run from it so its and easy addition but the /home may be moved later when new File Servers are put in place.
72-Node IB Network or RoCE?
The original FDR network allowed for 108 nodes. After examining what exactly was connected, it was determined that many of these were Infiniband storage interfaces which are no longer supported on most new product offerings. With no Infiniband interface on the new storage it seamed that a large network was not needed. The next step down from 108 nodes is 72 nodes using 6 switches as shown below.
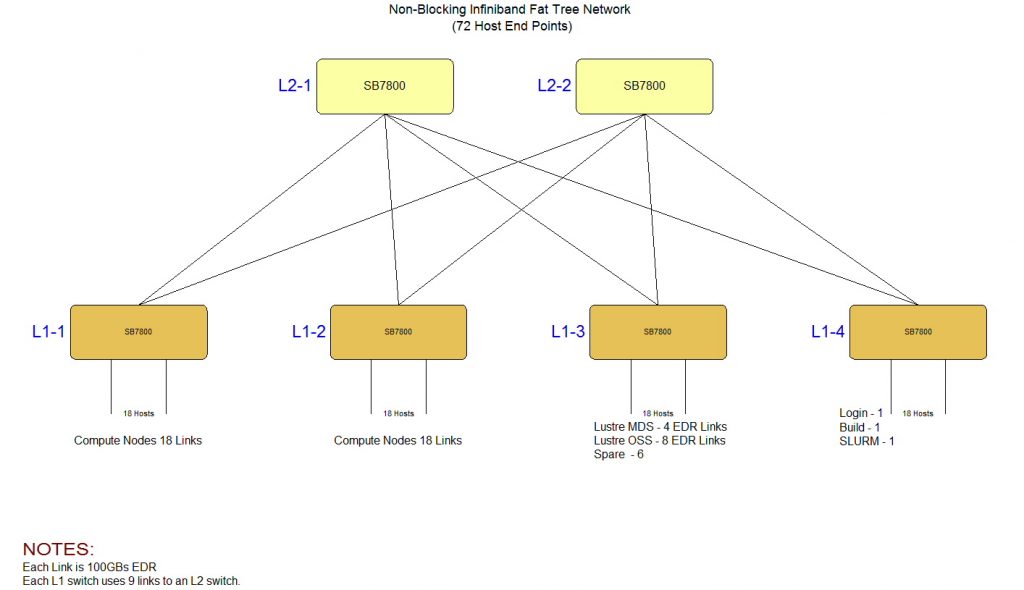
Soon into the project we accepted that the 72 node deployment was not going to be needed due to the minimal MPI workloads. So a new design was drafted using 100G Ethernet but running RDMA over Converged Ethernet (RoCE) rather than EDR Infiniband (IB). To link the Legacy nodes to the new storage, we would re-purpose one of the older SX6036 IB switches from the legacy system, this allowed legacy nodes to see the new storage. We will implement a Subnet Manager on one of the older management nodes so there are at least two SM’s running to configure the IB routing.
The key advantage of this is the ability to move back to EDR later as a result of specifying the Mellanox ConnectX5 VPI Cards.
New Compute Nodes
Selecting new Compute Nodes has been difficult, mainly choosing CPU’s, with the Intel 8278 series and AMD EPYC 64 core CPU being the top choices. There is also the combined power load of the newer high end CPU’s which limit how many servers will fit in a rack especially when you add 300W GPU cards in them.
We have identified three use cases for the new CPU’s:
- GPU Node with NVIDEA v100 cards and at least 512GB of RAM Minimum.
- An initial single Large Memory Node with at least 4TB of RAM.
- and Dual Socket configurations for Compute Nodes with 256/512G of RAM.
At this stage we look like specifying Dell R6525 and R7525 servers with Mellanox ConnectX5 VPI Single Port Cards which will be configured as 100G RoCE (RDMA over Converged Ethernet). The Lustre Nodes will have Dual Port VPI cards so both the RoCE network and the Legacy Nodes can see storage.
Final Steps
When the new scheduler nodes are up and running and can talk to the new Compute Nodes, we will bring the older Compute Nodes across and cable them into both the management network using LACP trunks and re-purpose one of the older 36 port FDR switches so the older nodes can see the Lustre Storage and SLURM Management networks.
Final decision will be the configuration of the Job Queues after an analysis of the workloads over the past 12 months.
We have also proposed using Saltstack to push the cluster configuration data to all the nodes, the advantage is we can push the SLURM software and config as well as mounts and packages to all nodes as needed.
Metrics
Metrics will be gathered from all nodes into an Elastic stack and this will enable us to devise some cool metrics on HPC cluster resource usage in real time.

Final Designs Acceptance
Our client has accepted our design and gone to market! We will be bidding on the install and maintenance components shortly once they select the vendor.